**1.**目前主流的开源模型体系有哪些?
目前主流的开源LLM(语言模型)模型体系包括以下几个:
- GPT(Generative Pre-trained Transformer)系列:由OpenAI发布的一系列基于Transformer架构的语言模型,包括GPT、GPT-2、GPT-3等。GPT模型通过在大规模无标签文本上进行预训练,然后在特定任务上进行微调,具有很强的生成能力和语言理解能力。
- BERT(Bidirectional Encoder Representations from Transformers):由Google发布的一种基于Transformer架构的双向预训练语言模型。BERT模型通过在大规模无标签文本上进行预训练,然后在下游任务上进行微调,具有强大的语言理解能力和表征能力。
- XLNet:由CMU和Google Brain发布的一种基于Transformer架构的自回归预训练语言模型。XLNet模型通过自回归方式预训练,可以建模全局依赖关系,具有更好的语言建模能力和生成能力。
- RoBERTa:由Facebook发布的一种基于Transformer架构的预训练语言模型。RoBERTa模型在BERT的基础上进行了改进,通过更大规模的数据和更长的训练时间,取得了更好的性能。
- T5(Text-to-Text Transfer Transformer):由Google发布的一种基于Transformer架构的多任务预训练语言模型。T5模型通过在大规模数据集上进行预训练,可以用于多种自然语言处理任务,如文本分类、机器翻译、问答等。
这些模型在自然语言处理领域取得了显著的成果,并被广泛应用于各种任务和应用中。
**2.**prefix LM和causal LM区别是什么?
前缀语言模型,因果模型
Prefix LM其实是Encoder-Decoder模型的变体,为什么这样说?解释如下:
- 在标准的Encoder-Decoder模型中,Encoder和Decoder各自使用一个独立的Transformer
- 而在Prefix LM,Encoder和Decoder则共享了同一个Transformer结构,在Transformer内部通过Attention Mask机制来实现。
与标准Encoder-Decoder类似,Prefix LM在Encoder部分采用Auto Encoding (AE-自编码)模式,即前缀序列中任意两个token都相互可见,而Decoder部分采用Auto Regressive (AR-自回归)模式,即待生成的token可以看到Encoder侧所有token(包括上下文)和Decoder侧已经生成的token,但不能看未来尚未产生的token。
Causal LM只涉及到Encoder-Decoder中的Decoder部分,采用Auto Regressive模式,直白地说,就是根据历史的token来预测下一个token,也是在Attention Mask这里做的手脚。
- Prefix LM:前缀语言模型是一种生成模型,它在生成每个词时都可以考虑之前的上下文信息。在生成时,前缀语言模型会根据给定的前缀(即部分文本序列)预测下一个可能的词。这种模型可以用于文本生成、机器翻译等任务。
- Causal LM:因果语言模型是一种自回归模型,它只能根据之前的文本生成后续的文本,而不能根据后续的文本生成之前的文本。在训练时,因果语言模型的目标是预测下一个词的概率,给定之前的所有词作为上下文。这种模型可以用于文本生成、语言建模等任务。
**3.**为何现在大模型大都是Decoder only?
Encoder的低秩问题:Encoder的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处。
更好的Zero-Shot性能、更适合于大语料自监督学习:decoder-only 模型在没有任何 tuning 数据的情况下、zero-shot 表现最好,而 encoder-decoder 则需要在一定量的标注数据上做 multitask finetuning 才能激发最佳性能。
4.大模型架构介绍?
Transformer 模型一开始是用来做 seq2seq 任务的,所以它包含 Encoder 和 Decoder 两个部分;他们两者的区别主要是,Encoder 在抽取序列中某一个词的特征时能够看到整个序列中所有的信息,即上文和下文同时看到;而 Decoder 中因为有 mask 机制的存在,使得它在编码某一个词的特征时只能看到自身和它之前的文本信息。
5.什么时候用Bert,什么时候用LLama,chatGLM
- Bert模型:Bert是一种预训练的语言模型,适用于各种自然语言处理任务,如文本分类、命名实体识别、语义相似度计算等。如果你的任务是通用的文本处理任务,而不依赖于特定领域的知识或语言风格,Bert模型通常是一个不错的选择。Bert由一个Transformer编码器组成,更适合于NLU相关的任务。
- LLaMA模型:LLaMA(Large Language Model Meta AI)包含从 7B 到 65B 的参数范围,训练使用多达14,000亿tokens语料,具有常识推理、问答、数学推理、代码生成、语言理解等能力。LLaMA由一个Transformer解码器组成。训练预料主要为以英语为主的拉丁语系,不包含中日韩文。所以适合于英文文本生成的任务。
- ChatGLM模型:ChatGLM是一个面向对话生成的语言模型,适用于构建聊天机器人、智能客服等对话系统。如果你的应用场景需要模型能够生成连贯、流畅的对话回复,并且需要处理对话上下文、生成多轮对话等,ChatGLM模型可能是一个较好的选择。ChatGLM的架构为Prefix decoder,训练语料为中英双语,中英文比例为1:1。所以适合于中文和英文文本生成的任务。
6.为什么增量预训练?
预训练学知识,指令微调学格式,强化学习对齐人类偏好,所以要想大模型有领域知识,得增量预训练(靠指令微调记知识不靠谱,不是几十w条数据能做到的)。
7,训练框架?
- 超大规模训练:选用 3D 并行,Megatron-Deepspeed拥有多个成功案例
- 少量节点训练:选用张量并行,但张量并行只有在 nvlink 环境下才会起正向作用,但提升也不会太明显。
- 少量卡训练:如果资源特别少,显存怎么也不够,可以使用 LoRA 进行增量预训练。
8.增量预训练?
垂直领域预训练有三种思路:
- 先用大规模通用语料预训练,再用小规模领域语料二次训练
- 直接进行大规模领域语料预训练
- 通用语料比例混合领域语料同时训练
13.简单介绍强化学习?
强化学习(Reinforcement Learning,RL)研究的问题是智能体(Agent)与环境(Environment) 交互的问题,其目标是使智能体在复杂且不确定的环境中最大化奖励(Reward)。
14.简单介绍下RLHF?
基于人类反馈对语言模型进行强化学习
预训练语言模型(收集样本数据,有监督微调):在人类标注的数据上微调出来的模型叫做 有监督的微调(supervised fine-tuning),这是训练出来的第一个模型
-
训练奖励模型
(收集排序数据,训练奖励模型):
- 给定一个问题,让上一步训练好的预训练模型 SFT 生成答案
- GPT 每一次预测一个词的概率,可以根据这个概率采样出很多答案,通常来说可以用 beam search
- 这里生成了四个答案,然后把这四个答案的好坏进行人工标注,进行排序标注
- 有了这些排序之后,再训练一个奖励模型(Reward Model,RM),这个模型是说给定 prompt 得到输出,然后对这个输出生成一个分数,可以认为这个分数是一个奖励或者是打分,使得对答案的分数能够满足人工排序的关系(大小关系保持一致),一旦这个模型生成好之后,就能够对生成的答案进行打分
用强化学习微调(使用RM模型优化SFT模型):继续微调之前训练好的 SFT模型,使得它生成的答案能够尽量得到一个比较高的分数,即每一次将它生成的答案放进 RM 中打分,然后优化 SFT 的参数使得它生成的答案在 RM 中获得更高的分数。
15.如何解决三个阶段寻来你SFT->RM->PPO过程较长,更新迭代慢问题?
要解决三个阶段训练过程较长、更新迭代较慢的问题,可以考虑以下几种方法:
- 并行化训练:利用多个计算资源进行并行化训练,可以加速整个训练过程。可以通过使用多个CPU核心或GPU来并行处理不同的训练任务,从而提高训练的效率和速度。
- 分布式训练:将训练任务分发到多台机器或多个节点上进行分布式训练。通过将模型和数据分布在多个节点上,并进行并行计算和通信,可以加快训练的速度和更新的迭代。
- 优化算法改进:针对每个阶段的训练过程,可以考虑改进优化算法来加速更新迭代。例如,在SFT(Supervised Fine-Tuning)阶段,可以使用更高效的优化算法,如自适应学习率方法(Adaptive Learning Rate)或者剪枝技术来减少模型参数;在RM(Reward Modeling)阶段,可以使用更快速的模型训练算法,如快速梯度法(Fast Gradient Method)等;在PPO(Proximal Policy Optimization)阶段,可以考虑使用更高效的采样和优化方法,如并行采样、多步采样等。
- 迁移学习和预训练:利用迁移学习和预训练技术,可以利用已有的模型或数据进行初始化或预训练,从而加速训练过程。通过将已有模型的参数或特征迁移到目标模型中,可以减少目标模型的训练时间和样本需求。
- 参数调优和超参数搜索:对于每个阶段的训练过程,可以进行参数调优和超参数搜索,以找到更好的参数设置和配置。通过系统地尝试不同的参数组合和算法设定,可以找到更快速和高效的训练方式。
16.怎样构建基于LLM的Agents?
Agent = LLM + Prompt Recipe + Tools + Interface + Knowledge + Memory
- Prompt Recipe:特定的内容要求、目标受众、所需的语气、输出长度、创造力水平等。
- Tools:工具集成允许通过API和外部服务完成任务。Agents 能够理解自然语言、推理提示、积累记忆并采取明智的行动。但是,Agents 的表现和一致性取决于他们收到的提示的质量。
- Knowledge:知识适用于所有用户的一般专业知识。知识扩展了LLM的内容。一般分为专业知识、常识知识和程序知识。
- Memory:单个用户或单个任务的上下文和记录细节。分为短期记忆和长期记忆。记忆服务与特定用户,在时间维度的体验。使特定用户的上下文对话个性化同时保持多步骤任务的一致性。记忆侧重暂时的用户和任务细节。
17.LLM Agents有哪些类型?
一般来说 LLM Agents 分为**会话型 Agents *和*任务型 Agents,两者在目标、行为和prompt方法都有重要区别。 会话型专注于提供引人入胜的个性化讨论,任务型致力于完成明确定义的目标。
Conversational Agents:模拟人类对话,能够在讨论中反映人类的倾向。允许细致入微的上下文交互,会考虑语气、说话风格、领域知识、观点和个性怪癖等因素。agent的开发者可以持续增强记忆、知识整合提高响应能力,持续优化应用。
Task-Oriented Agents:实现目标驱动,利用模型的能力分析prompt、提取关键参数、指定计划、调用API、通过集成tools执行操作,并生成结果回复。Prompt 工程把目标型Agents拆分成如下环节:制定战略任务、串联思路、反思过去的工作以及迭代改进的方法。
18.如何给LLM注入领域知识?
给LLM(低层次模型,如BERT、GPT等)注入领域知识的方法有很多。以下是一些建议:
- 数据增强:在训练过程中,可以通过添加领域相关的数据来增强模型的训练数据。这可以包括从领域相关的文本中提取示例、对现有数据进行扩充或生成新的数据。
- 迁移学习:使用预训练的LLM模型作为基础,然后在特定领域的数据上进行微调。这样可以利用预训练模型学到的通用知识,同时使其适应新领域。
- 领域专家标注:与领域专家合作,对模型的输出进行监督式标注。这可以帮助模型学习到更准确的领域知识。
- 知识图谱:将领域知识表示为知识图谱,然后让LLM模型通过学习知识图谱中的实体和关系来理解领域知识。
- 规则和启发式方法:编写领域特定的规则和启发式方法,以指导模型的学习过程。这些方法可以是基于规则的、基于案例的或基于实例的。
- 模型融合:将多个LLM模型的预测结果结合起来,以提高模型在特定领域的性能。这可以通过投票、加权平均或其他集成方法来实现。
- 元学习:训练一个元模型,使其能够在少量领域特定数据上快速适应新领域。这可以通过在线学习、模型蒸馏或其他元学习方法来实现。
- 模型解释性:使用模型解释工具(如LIME、SHAP等)来理解模型在特定领域的预测原因,从而发现潜在的知识缺失并加以补充。
- 持续学习:在模型部署后,持续收集领域特定数据并更新模型,以保持其在新数据上的性能。
- 多任务学习:通过同时训练模型在多个相关任务上的表现,可以提高模型在特定领域的泛化能力。
19.介绍TF-IDF算法
TF-IDF是一种用于信息检索与文本挖掘的常用加权技术,TF表示词频,即一个词在文档中出现的频率,IDF是逆文档频率,用来减少所有文档中常见词的权重.TF-IDF随着词在文档中出现的次数增加二增加,但会随着该词在语料库中的文档频率增加而减少,有助于高亮文档中的重要词汇。
20.问:什么是强化学习自人类反馈(RLHF),它在大模型训练中的应用是什么?
答:强化学习自人类反馈(RLHF)是一种结合了监督学习和强化学习的技术,它使用人类生成的反馈来指导模型的学习过程。在大模型训练中,RLHF被用于微调模型,以执行特定的任务或改进特定的性能指标,如对话生成的连贯性和相关性,通过这种方式,模型学习根据人类的偏好和反馈来调整其行为。
21.问:PPO(Proximal Policy Optimization)算法的基本原理是什么?
答:PPO算法是一种在策略空间进行优化的强化学习方法,旨在通过限制策略更新步骤的大小来避免训练过程中的性能崩溃。PPO通过引入一个代理目标函数来优化策略,该函数鼓励小幅更新策略,同时避免过大的偏离原始策略。
22.问:DPO(分布式策略优化)在RLHF中的核心思想是什么? 答:DPO的核心思想是通过优化策略的概率分布而不仅仅是期望值来提高策略的鲁棒性和性能。它考虑了环境的不确定性和模型的探索性,通过优化策略的整个分布来寻找最优策略,从而在RLHF中实现更高效和稳定的学习。
Q1: Transformer
中的编码器和解码器有什么区别,只有编码器或者只有解码器的模型是否有用?
A1: Transformer 中编码器(Encoder)和解码器(Decoder)的区别:
| 项目 | 编码器 (Encoder) | 解码器 (Decoder) |
|---|---|---|
| 输入 | 原始输入序列(如一段英文、图片特征等) | 目标输出序列的已有部分(如已翻译的前几个词) |
| 主要功能 | 将输入序列编码成高维的连续表征(上下文向量) | 基于编码器输出和已生成的内容一步步生成目标序列 |
| 结构特点 | 只看输入,不看输出 | 既看之前生成的输出(自回归, Masked Self-Attention |
| ),又看编码器的输出(Encoder-Decoder Attention) | ||
|---|---|---|
| 注意力类型 | 正常自注意力(Self-Attention) | Masked Self-Attention + Encoder-Decoder Attention |
| 应用场景 | 文本分类、特征提取、理解类任务 | 文本生成、翻译、总结、对话等任务 |
只有编码器(Encoder-only)的模型 代表: BERT
、 RoBERTa、 DeBERTa 用途: 理解型任务(分类、问答、检索、文本匹配) 特点: 输入整体一次性处理,不涉及逐步生成。
只有解码器(Decoder-only)的模型 代表: GPT 系列(GPT-2, GPT-3, GPT-4)、 LLaMA、 Mistral
用途: 生成型任务(写作、对话、翻译、总结) 特点: 逐步生成,每次基于已有输出预测下一个 token。
编码器-解码器(Encoder-Decoder)模型 代表: 原版 Transformer、 T5
用途: 既需要理解输入、又需要生成输出的复杂任务(如机器翻译)。
Q2: GPT 跟原始 Transformer 论文的模型架构有什么区别?
A2: GPT 跟原始 Transformer 论文模型的主要区别
| 项目 | 原始 Transformer(2017年论文) | GPT(以 GPT-1 为例) |
|---|---|---|
| 结构 | 编码器 + 解码器 | 只有解码器 |
| 输入输出 | 输入一个序列(编码器)-> 输出另一个序列(解码器) | 输入不完整的序列,预测下一个 token(自回归) |
| 注意力机制 | 编码器使用普通 Self-Attention,解码器用 Masked Self-Attention + Cross-Attention |
| 只用 Masked Self-Attention | ||
|---|---|---|
| Mask 处理 | 编码器的 Self-Attention 是标准的(可以看全局),解码器内部 Mask 未来的信息 | 整个模型 Mask 未来的信息,防止看见未来 token |
| 训练目标 | 给定输入序列,预测输出序列(通常是机器翻译任务) | 语言建模(自回归预测下一个 token) |
| 应用任务 | 机器翻译、摘要 | 生成文本、问答、对话 |
| 预训练策略 | 原论文没强调预训练(监督学习为主) | 明确使用预训练(大规模无监督语言建模) |
Q3: 仅编码器(BERT 类)、仅解码器(GPT 类)和完整编码器 - 解码器架构各有什么优缺点?
A3: 仅编码器架构(如 BERT) 特点:输入全局可见(双向 Attention),主要用于理解型任务(分类、问答、检索) 优点: 强大的理解能力,可以同时看到输入的前后文,建模上下文关系细腻。 适合判别类任务:如分类、抽取式问答、文本匹配、情感分析。 预训练效果好:Masked Language Model(MLM)任务易于优化和收敛。 缺点: 不适合生成任务:缺少左到右的自回归建模,不适合直接生成文本(如续写、翻译)。 推理时较慢:全局注意力计算量大,序列较长时开销高。
仅解码器架构(如 GPT) 特点:自回归生成(仅能看到自己之前的 token),主要用于生成型任务(续写、对话、代码生成) 优点: 擅长生成任务:自然符合从左到右逐字生成的需求。 推理友好:每次只用前缀,增量式推理速度快(利用缓存)。 训练简单:标准的语言模型目标(预测下一个 token)容易训练和优化。 缺点: 理解能力有限:缺少完整双向上下文,深层次理解弱于编码器模型。 长上下文难处理:纯解码器很难高效建模极长文本,尽管最近有改进(如 FlashAttention、MoE)。 训练数据量需求大:要训练出强理解能力,通常需要更大的数据量和更深层次微调。
编码器-解码器架构(如 T5、BART) 特点:编码器负责理解输入,解码器负责生成输出。双向编码器 + 单向自回归解码器。 优点: 兼具理解和生成能力:编码器处理全局信息,解码器逐步生成,适合复杂的生成任务(如翻译、摘要、复杂 QA)。 灵活性高:可以处理多种类型的输入-输出映射问题。 迁移性好:T5 这类模型可以被格式化成各种任务(统一成“文本到文本”)。 缺点: 训练和推理都较重:编码器和解码器都要跑,推理开销大于纯编码器或纯解码器。 推理速度慢:即使缓存了前缀,仍然需要编码完整输入,因此实时生成体验不如 GPT 类模型。 实现复杂度高:需要协调 encoder output 和 decoder input 之间的 attention。
Q4: 为什么说 Transformer 的自注意力机制相对于早期 RNN 中的注意力机制是一个显著的进步?
A4: 1.全局并行计算 在 RNN 中(比如 LSTM + Attention),序列是逐步处理的,时间步之间有严格的依赖关系,不能并行。Transformer 的自注意力机制允许一次性看到整个序列,每个位置可以并行计算注意力,大幅提高了训练速度和计算效率。 2.灵活建模长距离依赖 在 RNN 中,即使有注意力机制,捕捉很远距离的信息仍然比较困难,容易出现梯度消失、难以关注远处的重要信息。自注意力机制直接在所有位置之间建连,不管是近的还是远的 token,都能很自然地互相影响,没有任何偏向于局部邻域的结构瓶颈。 3.统一且更简单的架构: RNN + Attention 通常是先用 RNN 提取隐状态,再单独加一个注意力层,整个模型更复杂、难以优化。Transformer 直接用多层自注意力+前馈神经网络堆叠而成,不再依赖 RNN,本身结构更简洁,也更容易扩展。 4.更好地支持长序列建模(理论上): 自注意力的计算复杂度是O(n*n),n是序列长度,虽然带来一定计算成本,但换来的是对长序列建模能力的极大提升。传统RNN对长序列往往性能迅速下降。 5.更强的位置编码和建模能力: Transformer通过加入位置编码(Positional Encoding)来补充位置信息,而不是靠序列顺序隐式建模,反而能更灵活地捕捉顺序和结构。
Q9: 大模型的分词器和传统的中文分词有什么区别?对于一个指定的词表,一句话是不是只有一种唯一的分词方式?
A9: 大模型的分词器(Tokenizer) vs 传统中文分词
| 项目 | 大模型分词器(比如BERT、GPT类) | 传统中文分词(比如jieba、THULAC) |
|---|---|---|
| 目的 | 把文本变成小块以供神经网络建模(建模单位可以是字、子词、字节对( BPE |
| )、甚至Unicode码点) | 把连续的汉字序列切成「词」级单位(符合自然语言理解习惯) | |
|---|---|---|
| 粒度 | 取决于预训练词表:可以是字、子词、词甚至子词片段,BPE、WordPiece、Unigram等方法 | 通常以词为基本单位,力求符合语言学定义的“词” |
| 依据 | 固定词表(vocab),以最大化匹配原则切分(例如BPE优先匹配长片段) | 依据语料库词频、语言规则、词典,甚至依靠统计模型、规则、或神经网络 |
| 目标优化 | 主要为了压缩词表大小、控制OOV(未登录词),且方便高效编码 | 主要为了符合人类语言习惯的自然理解和后续任务(如搜索引擎、机器翻译) |
| OOV处理 | 分成更小单位(比如子词、字符),尽量减少完全OOV | 传统分词遇到OOV就分成单字,或启发式切分 |
一般情况下,大模型的分词器在指定词表下,有且只有一种确定的分词方式。大模型的分词器(比如BPE, WordPiece, Unigram)要求:根据词表,采用贪心匹配(greedy match),总是尽可能匹配最长的片段(子词)。每一句话,在给定词表和确定的分词规则(通常是最长优先贪心)之下,分词结果是唯一的。
Q16:word2vec 的训练过程中,负例的作用是什么?
A16: word2vec有两种主流训练方法:CBOW(Continuous Bag of Words)和 Skip-gram。在 Skip-gram + Negative Sampling 模型中,负例的引入是为了提高训练效率。
- 减少计算量。不再对整个词表做softmax,只在小量的负例和正例上做二分类,每次训练只更新一小部分词向量(正例+少数负例的向量),速度快很多。
- 训练目标变成了二分类。训练变成了让模型学会判断,某两个词是否真的出现在上下文里。
- 让词向量学到区分性的表示。正确搭配的词在向量空间里靠近,错误搭配的词在向量空间里远离。
Q17: 传统的静态词嵌入(如 word2vec)与大模型产生的与上下文相关的嵌入相比,有什么区别?有了与上下文相关的嵌入,静态词嵌入还有什么价值?
A17: 传统静态词嵌入 vs 上下文相关词嵌入
| 项目 | 静态词嵌入(如 word2vec, GloVe) | 上下文相关词嵌入(如 BERT, GPT) |
|---|---|---|
| 嵌入向量 | 每个词只有一个固定向量,不管出现在哪儿 | 每次出现根据具体上下文生成不同的向量 |
| 例子 | “bank” 不管是“河岸”还是“银行”,都是同一个向量 | “bank” 在“river bank”和“investment bank”中向量不同 |
| 训练方式 | 预测局部上下文(word2vec)或基于统计共现矩阵(GloVe) | 通过掩蔽语言建模(BERT)或自回归语言建模(GPT)大规模训练 |
| 模型结构 | 简单的浅层神经网络 | 深层 Transformer 神经网络 |
| 表达能力 | 只能捕捉词与词的大致共现关系 | 能理解语义、歧义、多义词,细粒度的语境 |
静态词嵌入依然很有价值. 1.轻量 & 快速。不需要跑Transformer,推理速度非常快,适合小模型、边缘设备、资源受限环境。 2.低成本。训练、存储、使用成本都很低,适合中小型项目。 3.可解释性强。因为一个词只有一个向量,便于分析(比如做词向量可视化、聚类)。 4.先验知识迁移。静态词嵌入可以作为其他任务的初始化,提供良好的先验。 5.兼容传统方法。一些经典的 NLP (比如文本分类、信息检索、推荐系统)设计就是用固定embedding的。 6.适合小数据场景。没有大量标注数据、也没法finetune大模型时,静态词嵌入仍然可以快速起步。
Q19: 在 word2vec 等词嵌入空间中,存在 king - man + woman ≈ queen 的现象,这是为什么?大模型的词元嵌入空间是否也有类似的属性?
A19:词嵌入捕捉了语义和语法方向。word2vec的训练目标:出现在相似上下文中的词,它们的向量接近。word2vec的空间隐式学到了“属性方向”(例子中统治者身份保持不变,但性别变化)。
比较区分
| 项目 | word2vec等静态词嵌入 | 大模型(BERT、GPT)词元嵌入 |
|---|---|---|
| 嵌入性质 | 单一静态词向量,训练目标就是建空间 | 嵌入只是Transformer的初始输入,最终靠隐藏层动态调整 |
| 线性属性 | 显式存在,比如king-man+woman≈queen | 初始嵌入层弱一些,但隐藏层表达更强、更动态 |
| 空间结构 | 比较干净的线性结构 | 嵌入更复杂,混合了语义、位置、句法等多种特征 |
| 词义处理 | 靠邻居分布建模,弱上下文敏感 | 高度上下文敏感,后续动态调整 |
word2vec构造了一个干净、线性化的词义空间,属性变化可以直接用向量加减模拟。大模型(BERT/GPT)虽然在初始词元嵌入层线性关系弱一些,但在经过Transformer处理后,可以以更复杂且灵活的方式捕捉到这些关系。大模型不是没有这种现象,而是以一种更深层、更动态的方式实现了。
Q20: 大模型怎么知道它的输出该结束了?
A20:1. 特殊的结束标记。训练数据里每一段文本通常都会加上一个特殊的“结束符号”
- 学到的结束策略。模型在学习“什么场景下该结束”:问答任务里,回答完一句话就该停;写故事任务里,写到合理收尾就停。这不是显式规则,是通过海量数据里的自然停顿规律,统计式学到的。
- 解码阶段的辅助规则。推理时会配合一些人为的限制:设置最大输出长度;输出了
立刻停止;连续重复(例如一直输出同一个词),可以触发停止。
Q21: 训练时如何防止模型看到未来的词元?
A21:主要靠causal mask。训练时,对注意力矩阵(self-attention)应用一个上三角掩蔽矩阵。
Q22: 注意力机制是如何计算上下文各个词元之间的相关性的?每个注意力头是只关注一个词元吗? softmax之前为什么要除以 sqrt(Dk)?
A22: (1).Self-Attention 机制。计算过程,点积 → 归一化(softmax)→ 加权求和。 (2).不是。每个 Attention Head独立地 用一套自己的QKV,在整句话(上下文)上做 self-attention。每个 head 也是关注整句话,不是只看一个词元。有的 head 更关注句法结构;有的 head 更关注相邻词;有的 head 关注长距离依赖。 (3).QK的点积较大,softmax的输出越接近one-hot(尖锐不平滑),这样导致梯度会变得很小(梯度消失问题)。避免梯度消失,保持训练稳定。
Q23:Q 和 K 在注意力的表达式里看起来是对称的,但 KV 缓存里为什么只有 KV,没有 Q ?
A23:K 和 V 是和“上下文”有关的,是"过去"积累下来的。Q 是跟"当前要生成的新词元"有关的,是"现在"动态计算的。在推理阶段,比如生成文本时,是token-by-token地生成的。以前已经生成过的词元的 K 和 V 是确定的,不需要重新计算,可以直接缓存到KV Cache里。Q 依赖的是新的输入,每次推理时都要新计算一次(根据当前的输入算出来,Prompt + 已生成的部分),它不能缓存下来用。
Q25: 为什么 Transformer 中需要残差连接?
A25:
- 缓解深层网络中的梯度消失问题。残差连接让梯度可以直接流到前面的层,保证反向传播时梯度不会因为层数多而消失。
- 促进特征的直接传播,保留输入信息。比如序列的位置关系,避免在子层处理后被扭曲。残差连接能让模型保留原始输入的关键信息,即使子层做了复杂的变换,可以通过直接加回输入,保持模型理解的稳定性。
- 加速收敛,提高训练稳定性。实验表明,没有残差连接的 Transformer 很难训练,容易震荡或停滞。
- 帮助学习细粒度调整。残差连接让子层只需要学习输入的微小修正,而不是从零开始学习新的复杂表示。
Q26: Transformer 中的 LayerNorm 跟 ResNet 中的 BatchNorm 有什么区别,为什么 Llama-3 换用了 RMSNorm ?
A26:LayerNorm vs BatchNorm
| 对比项 | LayerNorm(Transformer常用) | BatchNorm(ResNet常用) |
|---|---|---|
| 归一化维度 | 特征维度(每个样本内部归一化) | 批量维度(跨样本归一化) |
| 公式 | 对每个样本的每个通道归一化 | 对每个通道在整个batch中归一化(跨样本) |
| 依赖 Batch Size | 不依赖(单个样本也能用) | 依赖(小batch时效果差) |
| 主要应用场景 | NLP(Transformer) | 视觉(CNN,大batch) |
| 使用的位置 | 通常在残差连接之前或之后(取决于PreNorm/PostNorm) | 通常在卷积后、激活函数前 |
| 训练时推理时行为 | 一致(训练/推理行为一样) | 训练用batch统计,推理用滑动平均统计 |
LayerNorm是减均值后除以标准差,需要计算均值和方差,对数值波动更敏感(受均值影响),计算稍慢。RMSNorm只除以均方根,只需要均方差,省掉了减均值,更稳定计算更快。 Llama-3 用 RMSNorm的原因:加速推理,少了减均值的操作,计算量更小;数值稳定性,大模型的 hidden size 通常很大,均值的波动微不足道,还能让归一化更简单稳定;经验上效果好,实验发现用 RMSNorm loss 降得更快,收敛稳定性也好于 LayerNorm。
Q27: Transformer 中前馈神经网络的作用是什么?注意力层中已经有 softmax 非线性层,那么前馈神经网络是否必要?
A27:前馈神经网络的作用 增加模型的表达能力:注意力层主要是信息聚合(“看哪里”),FFN 提供非线性变换和特征加工(“怎么理解”)。 逐位置特征提炼:FFN 对每个 token 独立处理,不引入新的跨token依赖,属于位置上的深度加工。 引入额外的非线性:Attention用了 Softmax,它本身只在注意力权重上引入非线性,对value做的是加权平均;FFN是对每个 token 自身进行独立的非线性映射。
| 项目 | Attention(Softmax部分) | FFN |
|---|---|---|
| 非线性位置 | 只作用在权重(query-key相关性) | 直接作用在每个 token 的表示 |
| 加工内容 | 聚合不同 token 的信息(关注哪里) | 逐 token 变换特征(理解和丰富每个 token) |
| 是否改变 token 内部信息 | 否,value 是线性加权的 | 是,改变每个 token 的内容 |
| 是否独立于其他 token | 否,相互依赖(通过 attention 权重) | 是,每个 token 自己处理自己 |
| 表达能力提升 | 提高 token 间交互能力 | 提升 token 自身理解能力 |
实验上佐证:如果你把 Transformer 的 FFN 拿掉,模型性能通常会大幅下降。Attention 负责交互,FFN 负责加工;Attention 聚合信息,FFN 理解信息。二者是互补的,缺一不可。
Q40: 如何基于表示模型生成的嵌入向量实现文本分类?
A40:用表示模型提取文本的向量表示。取 [CLS] token 的输出;或者mean-pooling(平均池化)整个最后一层的token embeddings。 在嵌入向量上进行分类。加一层简单的分类器, MLP(多层感知机)或者可以直接一层线性层(Linear)+ Softmax。 用标准的有监督学习,可以冻结表示模型,只训练分类头(少量数据时推荐);还可以微调表示模型,一起训练(大量数据时效果更好)。
Q41: 使用嵌入向量实现分类和使用生成模型直接分类的方法相比,有什么优缺点?
A41:
| 维度 | 嵌入向量分类(Embedding + Classifier) | 生成模型直接分类(例如prompt+decoder生成类别) |
|---|---|---|
| 机制 | 提取文本嵌入,堆一个分类头(Linear/MLP) | 把分类问题当成生成任务,直接输出类别文本 |
| 训练数据需求 | 标准监督数据(X, y对) | 可以用少量示例(Few-shot Prompting),或者指令微调 |
| 推理速度 | 非常快(只跑一次前向传播+一层分类器) | 相对慢(需要 auto-regressive decoding,逐步生成) |
| 推理成本 | 极低 | 较高(尤其是长文本或类别多时) |
| 分类精度 | 如果训练得好,通常非常高且稳定 | 小样本时灵活性高,但易受提示词格式、类别名称影响 |
| 类别数量 | 类别数目可以很大 | 类别数过多时容易出错,生成式模型对output空间敏感 |
| 扩展性(加新类) | 需要重新训练分类头 | Prompt式可以直接添加新类别(零样本 Zero-shot) |
| 可解释性 | 直接看Logits或Softmax分布,清晰 | 文本生成过程可解释,但易受噪声干扰 |
| 应用场景适配 | 适合固定类别、数据量中等以上 | 适合小样本(Few-shot)、零样本(Zero-shot)任务 |
| 对表示模型依赖 | 需要一个好的embedding(SentenceBERT等) | 需要一个强大的生成模型(T5、GPT、LLaMA等) |
Q47: 使用生成模型进行文本分类时,以下三个提示词哪个会更有效? – “Is the following sentence positive or negative?” – “Classify the sentiment of this movie review as positive or negative.” – “You are a sentiment analysis expert. Given a movie review, determine if it expresses a positive or negative opinion. Return only the label ‘positive’ or ‘negative’.”
A47:第三个提示词更优 角色指令(Role Prompting):设定为“情感分析专家”有助于激活模型相关知识,提升任务专注度。 任务上下文(Task Context):指出是“电影评论”的情感分类,提供了必要的背景信息。 输出约束(Output Constraint):要求只返回“positive”或“negative”可减少生成干扰项,如解释或附加句子。
Q49: 给定大量的文档,如何把它们聚类成几簇,并总结出每一簇的主题?
A49:
- 文本预处理。分词、去停用词、词干还原,提高表示质量。
- 向量化。将文本转换为向量(如TF-IDF或者BERT Embedding),便于后续计算相似度。
- 聚类。使用KMeans(需指定簇数)、HDBSCAN(无需指定簇数,支持异常点)算法将向量聚为若干簇,得到每篇文档所属的簇标签。
- 主题提取。每簇内提取关键词或短语,如TF-IDF(提取每簇中TF-IDF最高的词语)、TextRank、LLM摘要(LLM生成摘要或标题),得到每一簇的主题描述。
Q50: 词袋法和文档嵌入在实现原理上有什么区别?词袋法是不是一无是处了?
A50:词袋法 vs 文档嵌入
| 特性 | 词袋法(BoW / TF-IDF) | 文档嵌入(BERT / SBERT / Doc2Vec 等) |
|---|---|---|
| 表示方式 | 稀疏向量,按词频统计 | 稠密向量,基于语义建模 |
| 维度 | 词汇表大小(几千到几万) | 固定维度(如768) |
| 上下文感知 | ❌ 不考虑词序、上下文 | ✅ 编码上下文语义 |
| 一词多义处理 | ❌ “bank”总是一个维度 | ✅ 根据上下文动态调整 |
| 语义相似性建模 | 差,更多依赖词面重合 | 强,能捕捉同义语义 |
| 计算资源 | ✅ 快速低成本 | ❌ 相对耗资源(需预训练模型) |
| 可解释性 | ✅ 易解释:某词重要性高 | ❌ 向量难以解释 |
| 适用任务 | 简单分类、检索基线 | 语义匹配、问答、摘要、聚类等 |
词袋法依然有以下价值: 1.快速、轻量、易部署。无需深度学习框架,也不用GPU,适合资源受限场景。 2.可解释性强。每个维度就是一个词,TF-IDF值能直观反映“关键词权重”。 3.在简单任务上仍有不错表现。如新闻分类、垃圾邮件识别、产品评论情感分析等任务的小规模实验中,TF-IDF + 逻辑回归仍常作为有效基线。 4.适合稀疏特征组合建模。与结构化数据结合建模(如推荐系统中的用户行为标签)。
Q59: 针对翻译类任务、创意写作类任务、头脑风暴类任务, temperature 和 top_p
分别该怎么设置?如何验证你选择的参数设置是否最优?
A59:在大语言模型(LLM)中,temperature 和 top_p 是控制采样多样性与输出确定性的两个重要参数。temperature:控制采样的随机性。越高越随机,越低越确定(趋近于贪婪解码)。通常范围为 [0.0, 1.5]。 top_p:控制采样的保留概率质量。当 top_p=0.9 时,仅在累计概率达 0.9 的词表子集内采样。也叫 nucleus sampling
。
不同任务的推荐设置
| 任务类型 | 推荐 temperature | 推荐 top_p | 原因说明 |
|---|---|---|---|
| 翻译类任务(准确性强) | 0.2 ~ 0.5 | 0.8 ~ 1.0 | 翻译结果需准确、可重复,过高温度会导致误译或不一致 |
| 创意写作任务(如故事、诗歌) | 0.7 ~ 1.0 | 0.9 ~ 1.0 | 创意写作追求多样性,允许模型自由“发挥” |
| 头脑风暴任务(如点子生成) | 0.8 ~ 1.2 | 0.9 ~ 1.0 | 需要模型跳出常规,多样性和创新性更重要 |
若使用 temperature=0,表示贪婪解码,只选概率最高的 token,输出稳定但缺乏多样性。
验证方式可分为主观评估和客观指标两类:
- 人工评估(主观)
采样多轮结果,人工打分对比以下指标:准确性(翻译、摘要等);流畅性(语言是否自然);多样性(输出是否重复,是否千篇一律);新颖性或有趣度(创意任务中) 可使用A/B测试或pairwise comparison(成对比较)方式进行盲评。
- 自动化指标(客观)
翻译类任务:BLEU、ROUGE、METEOR 等指标(需要参考答案) 创意/头脑风暴类:词汇多样性distinct-n(n-gram去重比例);Self-BLEU(低值表示更高的样本间多样性);Embedding-based metrics(BERTScore、MAUVE等)
Q62: 一个专业的提示词模板应该由哪几部分构成?为什么提示词中需要描述角色定义?
A62:专业提示词的标准结构
| 模块 | 描述 | 作用 |
|---|---|---|
| 1. 角色定义(Role definition) | 设定模型扮演的身份和专业性 | 限定语气风格、知识范围、输出可信度(减少幻觉) |
| 2. 任务目标(Task specification) | 明确说明需要模型完成什么任务 | 消除歧义,确保模型理解目标 |
| 3. 输入信息(Input context) | 提供参考材料或上下文信息(可选) | 限制模型只基于给定内容作答,避免编造 |
| 4. 输出格式(Output format) | 规定回答的结构或格式 | 增加可控性和一致性,便于后续处理或解析 |
| 5. 约束条件(Constraints) | 明确禁止行为、语言、领域边界 | 降低幻觉风险,减少跑题和“发明”内容 |
| 6. 示例或语气指导(Optional) | 给出正面/反面示例或语气要求 | 提升风格一致性,减少误解 |
Q81: 如果一个工具的调用时间较长,如何让智能体在等待工具调用返回前能够持续与用户交互或调用其他工具,并在工具调用返回时及时做出下一步动作?
A81:这个问题涉及 异步工具调用 + 多轮对话并发管理 的问题。涉及技术如下,
| 技术组件 | 作用 | 说明 |
|---|---|---|
| 异步工具调用(Async Tool Invocation) | 不阻塞主线程 | 工具调用应为异步(await/promise-based),使agent可以继续处理其他事件 |
| 任务ID / 请求标识符(Request ID) | 跟踪调用结果 | 为每次工具调用生成唯一标识,等结果回来后匹配上下文 |
| 事件调度器(Event Dispatcher) | 跳转控制流程 | 工具返回时触发对应处理逻辑,更新agent的工作状态 |
| 上下文管理器(Context Manager) | 维持会话状态 | 用于缓存等待中工具的状态、调用意图、与用户对话历史等 |
| 中间状态响应(Intermediate Reply) | 告知用户正在处理中 | 在等待期间与用户交互,如:“我正在为你查询××,这期间还需要我帮忙其他事吗?” |
| 动态任务切换(Task Switching) | 多任务管理 | 支持在等待期间处理新的用户请求、调用其他工具等 |
Q88: 在 RAG 中,为什么要把文档划分成多个块进行索引?如何解决文档分块后,内容上下文缺失的问题?如何处理跨片段的依赖关系?
A88:将文档划分成多个块进行索引
| 原因 | 说明 |
|---|---|
| 1. 提升检索精度 | 长文档中只有部分段落与用户查询相关,按块索引能避免整篇召回,提高精确度。 |
| 2. 控制嵌入长度 | 向量索引需要将文本转换为嵌入,大模型或编码器(如 BERT、MiniLM)有最大输入长度限制(如 512 token),必须切块。 |
| 3. 细粒度匹配 | 检索时,较小的文本块更容易与用户查询形成语义对齐(semantic match),提高召回质量。 |
| 4. 并行处理能力 | 多个文档块可以并行进行编码、索引与检索,提升系统吞吐率。 |
文档切块后导致上下文缺失的问题
| 方法 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 1. Overlapping Sliding Window | 使用滑动窗口法,每个块与前后有重叠区域(如前后各添加 50 token) | 保留局部上下文 | 会导致索引冗余、存储成本上升 |
| 2. Chunk-with-Title or Chunk-with-Headings | 每个块附带其所在标题或摘要,用作额外上下文 | 加强结构感知 | 对结构差文档效果有限 |
| 3. Chunk Expansion during Retrieval | 检索到一个 chunk 后,同时拉取其前后相邻的 chunk 一起作为 context 提供给生成模型 | 增强上下文整体性 | 检索系统需支持“chunk + delta”聚合 |
| 4. Hierarchical Embeddings / Long-context Embeddings | 为 chunk 编码时引入其上下文(如章节、标题、前文)到向量中,用更强的模型做全文感知 | 检索更准确 | 模型开销大,需预处理优化 |
| 5. Structured Memory / Index Augmentation | 构建图结构或高层次索引(如段落层索引 + 文档层索引),使得从 chunk 可追溯到文档层信息 | 保留完整语义关系 | 系统实现复杂度上升 |
处理跨片段的依赖关系,回答问题需要多个 chunk 的信息联合推理
| 方法 | 描述 | 示例 |
|---|---|---|
| 1. 多跳检索(Multi-hop Retrieval) | 第一次检索相关 chunk 后,从中提取线索再进行第二轮检索,形成推理链 | 先找人名 → 再找人名相关背景 |
| 2. 多段拼接输入生成(Context Fusion) | 将多个相关 chunk 拼接后输入生成模型,一次性输出答案 | Top-k chunk 拼接 |
| 3. Reranking + 合并重写 | 初步检索多个 chunk 后,对其重新排序、聚合成统一 context 再喂给生成器 | 用 Cross-Encoder reranker |
| 4. Retrieval Tree / Graph Reasoning | 构建 chunk 之间的知识图谱或树形结构,做结构化检索与 reasoning | 结合 Knowledge Graph |
| 5. Memory-Augmented Decoding | 将多个 chunk 存入外部 memory,通过读取 memory 支持跨 chunk 推理 | 用于复杂场景,如Agent对话 |
Q89: 如果发现向量相似度检索的匹配效果不佳,除了更换嵌入模型,还有哪些办法?
A89:嵌入质量优化
| 方法 | 说明 | 优点 |
|---|---|---|
| 1. Query & Document 标准化处理 | 对输入做清洗,如去除无意义词、格式统一、简化结构 | 减少语义噪音 |
| 2. Prompt Engineering for Embedding | 将文档 chunk 包装为“更具语义表达力”的格式,如加入标题、问题式表述等 示例:将 “Barack Obama was born in Hawaii.” 改为 “Where was Barack Obama born?” → Hawaii.” | 提高语义对齐,特别对 QA 检索效果提升显著 |
| 3. Embedding Augmentation | 将 chunk 的上下文(如标题、副标题、前文)一并编码 | 保留语义联系 |
| 4. 使用 Instruction-Tuned Embedding 模型 | 对于问答/对话类任务,尝试给嵌入模型加任务提示(如果模型支持) 如 E5 模型支持 query: xxx 和 passage: yyy | 增强语义对齐精度 |
检索策略优化
| 方法 | 说明 | 优点 |
|---|---|---|
| 1. Hybrid Retrieval(混合检索) | 向量检索 + BM25 结合 常用方法:Dense + Sparse,RRF(Reciprocal Rank Fusion)或加权融合 | 利用语义匹配与关键词匹配的互补性 |
| 2. Query Expansion | 在检索前对 query 做语义扩展:同义词、上下位词、重述等(可用 LLM 自动生成) | 提高 recall |
| 3. Query Rewriting | 利用大模型将 query 改写为更适合向量检索的语义形式 | 提高匹配相关性 |
| 4. 多轮检索(Iterative Retrieval) | 先用 embedding 粗筛 Top-N,基于结果再发起更精细检索(如 rerank) | 精度提升 |
索引机制与后处理优化
| 方法 | 说明 | 优点 |
|---|---|---|
| 1. Reranking(Cross-Encoder) | 用更强的双塔/交叉编码器对初始 Top-k 检索结果做 rerank | 显著提升 top-k 质量 |
| 2. Chunk Aggregation | 将邻近的 chunk 合并作为一个整体回答依据,提高语义连贯性 | 避免割裂内容误召回 |
| 3. Chunk Filtering | 对噪音块、空块、结构性弱的块预过滤掉,避免误检索 | 降低干扰项 |
| 4. Indexing with Metadata | 建立多维索引(如作者、类型、标签),支持 filter-based 精确控制 | 提高精准性与可控性 |
Q90: 向量相似度检索不能实现关键词的精确匹配,传统关键词检索不能匹配语义相近的词,如何解决这对矛盾?
A90: 将 稀疏(关键词)检索 和 稠密(向量)检索 结合起来,综合两者优点。
Q91: 向量相似度检索已经是根据语义相似度匹配,为什么还需要重排序模型?
A91: 向量检索是粗排,不是精排。向量检索阶段通常使用双塔架构(bi-encoder),query 和 document 分别独立编码成向量,用向量相似度(如 cosine 或 dot product)快速计算相似度。它的优点是速度快,可向量化索引。但缺点是:缺乏交互建模,不能精准理解细粒度语义关系。
Cross-Encoder(交叉编码器)架构排序 将 query 和每个候选文档拼接为一个整体输入模型(如 [CLS] query [SEP] document [SEP]),模型(如 BERT)可在 token 级别做 attention 建模。用 Dense 模型做候选召回(Recall) + Cross-Encoder 做精排(Rerank),RAG系统的最佳实践是“双阶段检索结构”
Q92: 为什么要在向量相似度检索前,对用户输入的话进行改写?
A92:向量检索依赖语义相似性,但用户 query 往往不具备良好表达。改写的核心目标是构造“嵌入友好型语义查询”。改写后的 query 更接近文档中的自然语言表达,因此匹配效果更佳。
Query 改写技术
| 方法 | 描述 | 工具/模型 |
|---|---|---|
| LLM 改写(prompt-based) | 用 GPT 类模型将原始 query 改写为自然语言问句、补全背景等 | ChatGPT, Claude, Gemini 等 |
| 规则改写 / 模板化 | 针对 FAQ、查询意图库做模板替换或补全 | 适合领域任务 |
| 多样性扩展(multi-turn query expansion) | 生成多个改写,做并行向量检索,增加 recall | Retrieval-augmented LLM |
| 提示式改写(Instruction-tuned Embedding) | 对 query 加上结构提示词,如 query: xxx(适用于 E5, GTE 等模型) | 提高语义对齐能力 |
1、全量微调
- **原理:**在预训练的大型模型基础上,对模型的所有层和参数进行调整,使其适应特定任务。
备注:微调时,使用较小的学习率和特定任务的数据进行
- **优点:**因为对模型的所有参数进行了调整,所以可以充分利用预训练模型的通用特征,能够较好地适应特定任务。
- **缺点:**计算成本较高,需要大量的计算资源和时间来训练模型,尤其是对于非常大的模型。
2、参数高效微调( PEFT
:Parameter-Efficient Fine-Tuning )
- 通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。
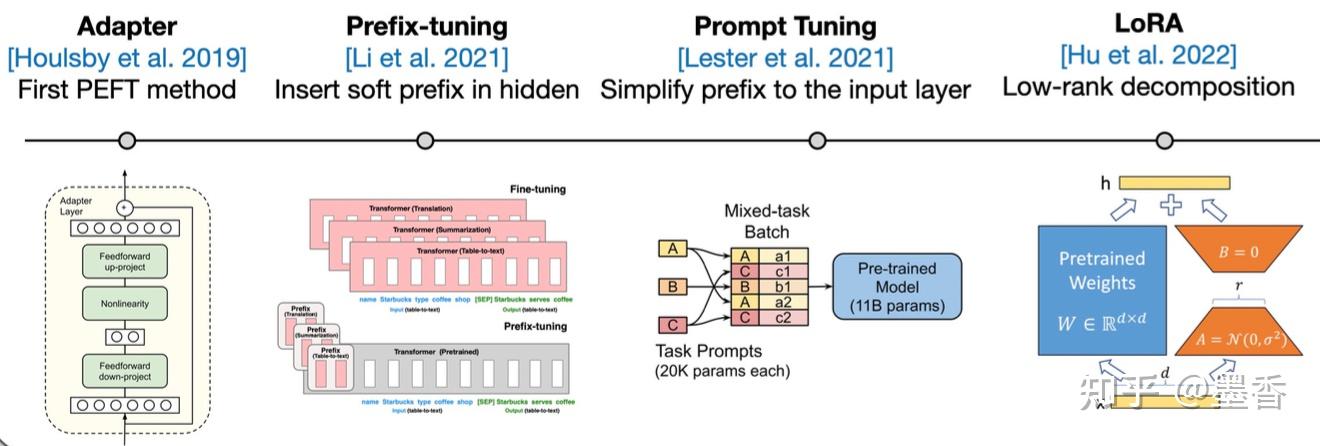
2.1 Adapter
Parameter-Efficient Transfer Learning for NLP 2019年,Houlsby N等人将Adapter引入NLP领域,作为全模型微调的一种替代方案。
- **原理:**在预训练模型的每一层(或某些层)中添加Adapter模块。微调时冻结预训练模型主体,由Adapter模块学习特定下游任务的知识。模型结构如下:
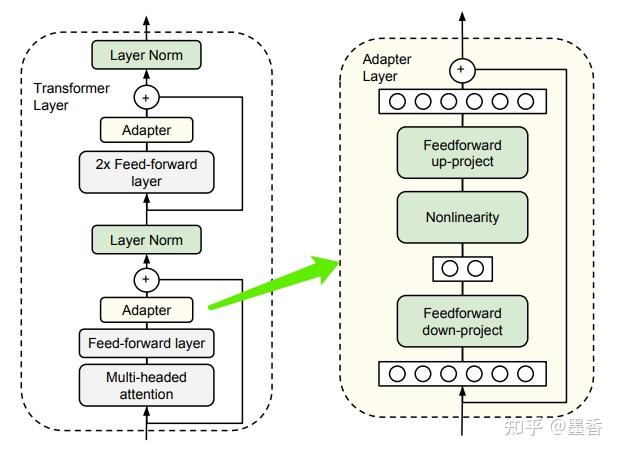
- **优点:**训练室,只需要训练Adapter模块的少量参数,大大降低了训练的计算成本和存储成本。同时,由于预训练模型的主体被冻结,保留了预训练模型的大部分知识,能够快速适应新的任务。
- **缺点:**增加网络深度,模型变得更复杂,影响模型的推理速度。
2.2 Prefix Tuning
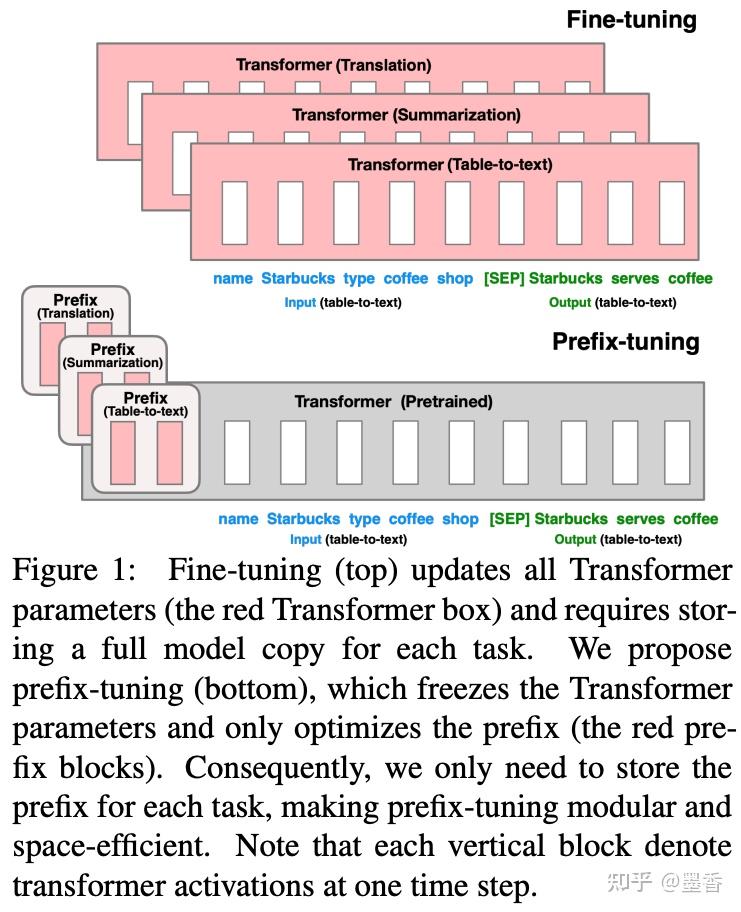
Prefix-Tuning: Optimizing Continuous Prompts for Generation https://github.com/XiangLi1999/PrefixTuning
原理:输入token之前构造一段任务相关的virtual tokens作为Prefix,在每个Transformer层的hidden states加入Prefix。在微调时,预训练模型的参数被冻结,只有prefix部分的参数进行更新。
2.3 Prompt Tuning
原理:通过在输入文本中添加提示信息,引导模型更好地理解任务,并根据提示信息进行预测。提示信息可以是一些特定的文本片段、关键词或者问题模板等,其目的是将下游任务转化为与预训练模型的预训练任务相似的形式,以便模型能够更好地利用预训练的知识。
Prefix Tuning和Prompt Tuning的区别: **Prompt Tuning:**在模型输入之前添加一个可学习的“提示”,也就是embedding层的前面 **Prefix Tuning:**将可学习的Prefix向量应用于模型的自回归部分(如Transformer的解码器部分),而非输入序列的开头。前缀向量被附加到自回归过程中的隐藏状态,并随着每次自回归步骤传播,影响整个解码过程。
2.4 LORA
**原理:**冻结预训练模型的矩阵参数,并引入额外的低秩矩阵来替代模型权重的变化。在下游任务时只更新这些低秩矩阵的参数,而保持预训练模型的大部分参数不变。
做的就是增加小参数模块去学习改变量ΔW
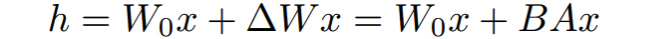
在训练过程中,W0是Frozen参数,A和B是update的训练参数。
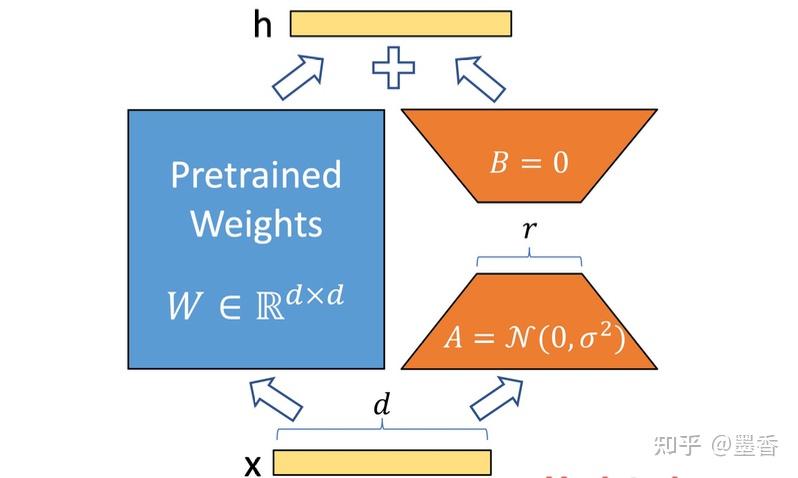
**缺点:**低秩假设可能并不完全适用于所有的任务和模型,在某些情况下可能无法达到与全量微调相当的性能。
1. 神经网络 (Neural Networks, NN)
核心思想: 神经网络受到人脑神经元工作方式的启发,是一种模拟生物神经网络结构和功能的数学模型。它通过大量连接的简单处理单元(称为神经元或节点)的协作来学习和表示复杂的模式。
基本结构:
-
神经元 (Neuron)
:神经网络的基本计算单元。每个神经元接收来自其他神经元或外部输入的信号,对这些信号进行加权求和,然后通过一个激活函数 (Activation Function) 处理,产生一个输出信号。
- 权重 (Weights):表示输入信号的重要性。
- 偏置 (Bias):一个额外的可调参数,允许激活函数输出的微调。
- 激活函数 (Activation Function):引入非线性,使得网络能够学习复杂模式。常见的激活函数有 Sigmoid、ReLU (Rectified Linear Unit)、Tanh 等。
-
层 (Layers)
:神经元被组织在不同的层中。
- 输入层 (Input Layer):接收原始数据(特征)。
- 隐藏层 (Hidden Layers):位于输入层和输出层之间,进行大部分的计算和特征提取。一个神经网络可以有零个、一个或多个隐藏层。“深度学习”通常指包含多个隐藏层的神经网络。
- 输出层 (Output Layer):产生最终的预测或分类结果。
-
连接 (Connections):神经元之间的连接,每个连接都有一个关联的权重。信息从输入层流向输出层(在前馈神经网络中)。
学习过程 (训练):
- 前向传播 (Forward Propagation):输入数据通过网络,从输入层逐层传递到输出层,计算出预测结果。
- 损失函数 (Loss Function):度量预测结果与真实标签之间的差异(误差)。
- 反向传播 (Backward Propagation):根据损失函数计算出的误差,从输出层反向传播回网络,并使用优化算法(如梯度下降)调整每个连接的权重和每个神经元的偏置,以最小化误差。
- 迭代 (Epochs):重复上述过程多次,直到模型的性能达到满意的水平。
优点:
- 能够学习非常复杂的数据模式和非线性关系。
- 在图像识别、自然语言处理等领域表现出色。
- 具有良好的泛化能力(在未见过的数据上表现良好),如果训练得当。
缺点:
- 需要大量的训练数据。
- 计算成本高,训练时间长。
- 模型通常是“黑箱”,难以解释其内部决策过程。
- 容易过拟合(在训练数据上表现好,但在新数据上表现差),需要正则化等技术来缓解。
2. 卷积神经网络 (Convolutional Neural Networks, CNN 或 ConvNet)
核心思想: CNN 是一种特殊类型的深度神经网络,特别适用于处理具有网格状拓扑结构的数据,例如图像(二维像素网格)和时间序列数据(一维信号网格)。它们通过引入卷积层和池化层来自动学习空间层级结构中的特征。
关键组件:
-
卷积层 (Convolutional Layer)
:
- 滤波器/卷积核 (Filter/Kernel):一个小型的权重矩阵,在输入数据上滑动(卷积操作),检测特定的局部特征,如边缘、角点、纹理等。
- 特征图 (Feature Map):滤波器在输入上卷积后产生的输出,表示特定特征在输入数据不同位置的激活程度。一个卷积层通常包含多个滤波器,学习多种特征。
- 参数共享 (Parameter Sharing):同一个滤波器在输入数据的不同位置使用相同的权重,大大减少了模型参数数量,提高了效率,并使网络对特征的位置具有一定的平移不变性。
-
池化层 (Pooling Layer) / 子采样层 (Subsampling Layer)
:
- 通常在卷积层之后,用于降低特征图的空间维度(宽度和高度),减少计算量和参数数量,从而控制过拟合。
- 最大池化 (Max Pooling):选取局部区域内的最大值作为输出。
- 平均池化 (Average Pooling):计算局部区域内的平均值作为输出。
- 池化操作有助于使特征表示更加鲁棒,对微小的位移和形变不敏感。
-
全连接层 (Fully Connected Layer)
:
- 通常位于 CNN 的尾部,在经过多次卷积和池化操作提取出高级特征后,全连接层将这些特征组合起来进行最终的分类或回归任务。其工作方式与传统神经网络中的层类似。
-
激活函数 (Activation Function):如 ReLU,通常在卷积层和全连接层之后使用,引入非线性。
工作流程: 输入数据(如图像)首先通过一系列交替的卷积层和池化层,以提取越来越复杂和抽象的特征。然后,这些高级特征被展平 (Flatten) 并输入到一个或多个全连接层中,最后通过输出层得到结果。
优点:
- 在图像识别、目标检测、图像分割等计算机视觉任务中取得了巨大成功。
- 能有效学习空间层次结构特征。
- 由于参数共享和池化,具有一定程度的平移、缩放和旋转不变性。
- 相比于传统全连接网络处理高维图像数据,参数数量大大减少。
缺点:
- 设计和调优 CNN 架构可能比较复杂。
- 仍然需要大量数据进行训练。
3. 循环神经网络 (Recurrent Neural Networks, RNN)
核心思想: RNN 是一类专门用于处理序列数据(如文本、语音、时间序列)的神经网络。与前馈神经网络不同,RNN 具有内部的“记忆”机制,允许信息在序列的不同时间步之间传递和保持。
关键特征:
- 循环连接 (Recurrent Connections):网络的输出不仅依赖于当前的输入,还依赖于先前时间步的隐藏状态(记忆)。隐藏状态会作为下一个时间步计算的一部分输入回网络自身。
- 隐藏状态 (Hidden State):可以看作是网络对到目前为止已处理序列信息的摘要或记忆。
- 时间步 (Time Steps):序列数据被分解成一系列时间步进行处理。在每个时间步,RNN 接收当前输入和前一时间步的隐藏状态,然后计算新的隐藏状态和当前输出。
工作流程: 对于一个输入序列 x1,x2,…,xT,RNN 会按顺序处理:
- 在时间步 t=1,RNN 接收 x1 和一个初始隐藏状态 h0(通常为零向量),计算出 h1 和输出 y1。
- 在时间步 t=2,RNN 接收 x2 和 h1,计算出 h2 和输出 y2。
- 以此类推,直到序列结束。在每个时间步,通常使用相同的权重参数集。
变体: 标准 RNN 存在梯度消失 (Vanishing Gradient) 和梯度爆炸 (Exploding Gradient) 的问题,这使得它们难以学习长距离依赖关系。为了解决这些问题,发展出了更复杂的 RNN 变体:
- 长短期记忆网络 (Long Short-Term Memory, LSTM):引入了门控机制(输入门、遗忘门、输出门)来控制信息的流动和记忆的更新,能更好地捕捉长期依赖。
- 门控循环单元 (Gated Recurrent Unit, GRU):LSTM 的一个简化版本,也使用门控机制,但参数更少,计算效率有时更高。
优点:
- 能够对序列数据建模,捕捉时间动态和上下文信息。
- 广泛应用于自然语言处理(如机器翻译、情感分析、语言模型)、语音识别、时间序列预测等。
缺点:
- 标准 RNN 难以训练和捕捉长期依赖。
- 训练过程可能较慢,尤其对于长序列。
- 并行计算不如 CNN 容易。
4. 决策树 (Decision Tree)
核心思想: 决策树是一种非参数的监督学习算法,可用于分类和回归任务。它通过学习一系列简单的决策规则(基于特征值)来将数据划分为不同的区域,最终得到预测结果。模型结构呈树状,因此得名。
结构:
- 根节点 (Root Node):代表整个数据集。
- 内部节点 (Internal Node):代表一个特征上的测试(决策规则)。
- 分支 (Branch/Edge):代表测试的结果。
- 叶节点 (Leaf Node/Terminal Node):代表一个类别标签(分类树)或一个数值(回归树)。
构建过程 (例如 ID3, C4.5, CART 算法):
- 特征选择:选择一个最优特征来分裂当前数据集。选择标准通常是基于信息增益 (Information Gain)、信息增益率 (Gain Ratio) 或基尼不纯度 (Gini Impurity) 等指标,目标是使得分裂后的子集尽可能“纯净”(即包含尽可能单一的类别)。
- 节点分裂:根据选定特征的不同取值将数据集分裂成多个子集,并为每个子集创建一个新的分支。
- 递归构建:对每个子集递归地重复步骤 1 和 2,直到满足停止条件(如节点中的所有样本属于同一类别、没有更多特征可用、达到预设的树深度等)。
预测过程: 从根节点开始,根据样本的特征值,沿着树的决策路径向下移动,直到到达一个叶节点,该叶节点的标签或值即为预测结果。
优点:
- 模型易于理解和解释,可以可视化。
- 数据预处理要求较低(例如,不需要特征缩放)。
- 能够处理数值型和类别型特征。
- 计算成本相对较低。
缺点:
- 容易过拟合,生成的树可能过于复杂,对训练数据中的噪声敏感。可以通过剪枝 (Pruning) 或设置停止条件来缓解。
- 对于特征之间存在复杂关系(如异或问题)的情况,可能表现不佳。
- 模型不稳定,数据微小的变动可能导致生成完全不同的树。
5. 随机森林 (Random Forest)
核心思想: 随机森林是一种集成学习 (Ensemble Learning) 方法,它通过构建多个决策树并将它们的预测结果进行组合(例如,分类任务中通过投票,回归任务中通过平均)来提高整体模型的性能、鲁棒性和准确性,并减少过拟合。
构建过程:
-
数据采样 (Bagging - Bootstrap Aggregating):从原始训练数据集中,通过有放回地随机抽样(Bootstrap sampling)来创建多个不同的子数据集。每个子数据集的大小与原始数据集相当,但由于是有放回抽样,某些样本可能出现多次,某些则可能不出现。
-
特征随机选择:在每个决策树的每个节点进行分裂时,不是从所有特征中选择最优特征,而是从随机选择的一个特征子集中选择最优特征。这增加了树之间的多样性。
-
构建多棵决策树:使用每个子数据集和特征随机选择策略,独立地构建多棵决策树。通常不进行剪枝,让树充分生长。
-
组合预测
:
- 分类任务:每棵树对新样本进行预测,最终类别由所有树投票决定(多数票原则)。
- 回归任务:每棵树对新样本进行预测,最终结果是所有树预测值的平均。
优点:
- 通常比单棵决策树具有更高的准确性和更好的泛化能力。
- 能有效减少过拟合。
- 能够处理高维数据,并且可以评估特征的重要性。
- 对缺失值不敏感。
- 训练过程可以并行化。
缺点:
- 模型复杂度比单棵决策树高,解释性有所下降(虽然可以评估特征重要性)。
- 对于非常高维且稀疏的数据(如文本数据),可能不如线性模型表现好。
- 训练和预测时间比单棵决策树长。
6. 支持向量机 (Support Vector Machine, SVM) 支持向量机 (Support Vector Machine, SVM)
核心思想: SVM 是一种强大的监督学习算法,主要用于分类任务,也可用于回归 (Support Vector Regression, SVR)。其核心思想是在特征空间中找到一个最优的超平面 (Hyperplane),该超平面能够将不同类别的数据点分隔开,并且使得离超平面最近的数据点(称为支持向量)到超平面的间隔 (Margin) 最大化。
关键概念:
-
超平面 (Hyperplane):在 n 维空间中,一个 n−1 维的子空间。例如,在二维空间中是一个直线,在三维空间中是一个平面。
-
间隔 (Margin):分隔超平面与最近的支持向量之间的距离。SVM 的目标是最大化这个间隔。更大的间隔通常意味着更好的泛化能力和鲁棒性。
-
支持向量 (Support Vectors):那些最接近决策边界(超平面)的数据点。它们是“支撑”起这个最优超平面的关键点,如果移动它们,超平面也会随之改变。
-
核技巧 (Kernel Trick)
:对于线性不可分的数据,SVM 可以通过核函数将数据映射到更高维的特征空间,使得数据在该高维空间中变得线性可分。常见的核函数有:
- 线性核 (Linear Kernel) 线性核
- 多项式核 (Polynomial Kernel) 多项式核
- 径向基函数核 (Radial Basis Function Kernel, RBF Kernel) - 非常常用 径向基函数核 - 非常常用
- Sigmoid 核
工作原理:
- 线性可分情况:找到一个能将数据完美分开并且间隔最大的超平面。
- 线性不可分情况(软间隔):允许一些数据点被错误分类或落在间隔内,通过引入一个惩罚参数 C 来平衡间隔最大化和分类错误最小化。C 越大,对误分类的惩罚越重,模型越倾向于正确分类所有点,可能导致间隔变小和过拟合。
- 非线性情况(核技巧):使用核函数将数据映射到高维空间,然后在高维空间中寻找线性超平面。
优点:
- 在高维空间中非常有效,即使维度数量大于样本数量。
- 由于只使用支持向量来定义决策边界,内存效率高。
- 通过选择不同的核函数,可以灵活地处理各种数据分布。
- 在许多分类问题上表现出色,泛化能力强。
缺点:
- 当特征数量远大于样本数量时,性能可能会下降(除非使用合适的核函数和正则化)。
- 对核函数的选择和参数(如 C 和 RBF 核的 γ)比较敏感,需要仔细调优。
- 对于大规模数据集,训练时间可能较长。
- 模型解释性不如决策树。