以下是近期与一些人谈话的收获做的整合:
web3其实是对生产关系的改良 但是AI却是对生产力的革命
你觉得无政府主义等想法非常前卫,很向往,是因为包括你在内的很多人都感受到了旧社会的结构性腐朽
web3的底层逻辑是“去中心化的生产关系” 解决资源的分配、信任和所有权问题 他们研究怎么切蛋糕 但随着经济下行 能够给人们去切的蛋糕越来越少 。最终沦为存量博弈的数字赌场 这也是为什么你觉得那里价值观扭曲的原因。用一句话来形容这个圈子非常准确:用最前卫的叙事包装最古老的贪婪
AI的发展极大程度优化了社会结构,极大幅度地提升了产能 编程、设计、分析,甚至是体力劳动。AI的渗透率极强,改变世界需要的是新的生产力去颠覆破旧的社会关系
所以咋说呢 你如果问我 什么能够让世界更合理 我相信web3肯定有一席之地(优化生产关系) 但如果你问我什么能够真正改变世界 那我一定会告诉你是人工智能(生产力革命)
不过一旦人工智能技术产生了更大的突破 世界已经被颠覆的时候 或许以web3为首的一众技术(量子计算潜力也很大哦)都会有所变革吧
默认hardhat框架,用的ts,配置环境不讲了
因为要在0g测试网上部署,现在hardhat.config.ts上加
const config: HardhatUserConfig = {
solidity: "0.8.20", // 匹配合约的编译器版本要求
networks: {
// 默认本地网络
hardhat: {
},
// 0G Testnet (Newton)
"og-testnet": {
url: "https://evmrpc-testnet.0g.ai", // 0G Testnet 官方 RPC
accounts: process.env.PRIVATE_KEY ? [process.env.PRIVATE_KEY] : [],
chainId: 16602,
},
},
};
注意先删去lock.sol,然后创建INFT.so合约
TRiSM for Agentic AI: A Review of Trust, Risk, and Security

暑假摸鱼看项目的时候顺便翻了翻某些官方文档
其实21号就考完试了,早就想开始动笔写点学期总结了,但碍于各种原因一直没能动笔,这学期放下心态对很多东西反而祛魅了,对技术的追求反而没有了开始的兴奋,原本幻想的发一作,大厂实习没有多少推进,面试了很多但止于背八股文和算法,被某实验室的mentor放鸽子,实验室工作也没什么推进,绩点爆炸,看了很多教程但一知半解,盲手搓是不会的,只会各种vibe coding技巧,好在暑假找了另一个科研实习岗,adventurex通过了审核(很快一周不到就过了?)竞赛也拿了牌子(水的),开始期待7月。
Word Embedding
One-hot表示
One-hot简称读热向量编码,也是特征工程中最常用的方法。其步骤如下:
- 构造文本分词后的字典,每个分词是一个比特值,比特值为0或者1。
- 每个分词的文本表示为该分词的比特位为1,其余位为0的矩阵表示。
每个词典索引对应比特位
CNN
| CNN层次结构 |
作用 |
| 输入层 |
卷积网络的原始输入,可以是原始或预处理后的像素矩阵 |
| 卷积层 |
参数共享、局部连接,利用平移不变性从全局特征图提取局部特征 |
| 激活层 |
将卷积层的输出结果进行非线性映射 |
| 池化层 |
进一步筛选特征,可以有效减少后续网络层次所需的参数量 |
| 全连接层 |
用于把该层之前提取到的特征综合起来。 |
1.1 输入层
在做输入的时候,需要把图片处理成同样大小的图片才能够进行处理。
强化学习算法分两种,(工作A)一种是预测每个状态的价值V,(工作B)一种是预测在每个状态下,所有可能出现的动作的价值(动作价值Q)
MC蒙特卡洛算法
完成A工作,增量更新,需要收集很多样本数据来参加训练,预测每个状态的价值
分词
深度学习模型期望数字作为输入,而不是英语句子!所以我们需要做两件事:
- Tokenization: Split each text up into words (or actually, as we’ll see, into tokens)
分词:将每段文本分割成单词(或者,实际上,我们会看到,分割成标记)
- Numericalization: Convert each word (or token) into a number.
数字化:将每个单词(或标记)转换为一个数字。
from datasets import Dataset,DatasetDict
ds = Dataset.from_pandas(df)
#选择模型
model_nm = 'microsoft/deberta-v3-small'
#分词
from transformers import AutoModelForSequenceClassification,AutoTokenizer
tokz = AutoTokenizer.from_pretrained(model_nm)
def tok_func(x): return tokz(x["input"])
tok_ds = ds.map(tok_func, batched=True)
分词器中有一个名为 vocab 的列表,其中包含每个可能的标记字符串的唯一整数。我们可以这样查找它们,例如,为了找到单词"of"的标记:
**1.**目前主流的开源模型体系有哪些?
目前主流的开源LLM(语言模型)模型体系包括以下几个:
- GPT(Generative Pre-trained Transformer)系列:由OpenAI发布的一系列基于Transformer架构的语言模型,包括GPT、GPT-2、GPT-3等。GPT模型通过在大规模无标签文本上进行预训练,然后在特定任务上进行微调,具有很强的生成能力和语言理解能力。
- BERT(Bidirectional Encoder Representations from Transformers):由Google发布的一种基于Transformer架构的双向预训练语言模型。BERT模型通过在大规模无标签文本上进行预训练,然后在下游任务上进行微调,具有强大的语言理解能力和表征能力。
- XLNet:由CMU和Google Brain发布的一种基于Transformer架构的自回归预训练语言模型。XLNet模型通过自回归方式预训练,可以建模全局依赖关系,具有更好的语言建模能力和生成能力。
- RoBERTa:由Facebook发布的一种基于Transformer架构的预训练语言模型。RoBERTa模型在BERT的基础上进行了改进,通过更大规模的数据和更长的训练时间,取得了更好的性能。
- T5(Text-to-Text Transfer Transformer):由Google发布的一种基于Transformer架构的多任务预训练语言模型。T5模型通过在大规模数据集上进行预训练,可以用于多种自然语言处理任务,如文本分类、机器翻译、问答等。
这些模型在自然语言处理领域取得了显著的成果,并被广泛应用于各种任务和应用中。
# 数据加载
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
X, Y = fetch_california_housing(return_X_y=True)
X.shape, Y.shape # (20640, 8), (20640, )
# 数据预处理
ones = np.ones(shape=(X.shape[0], 1))
X = np.hstack([X, ones])
validate_size = 0.2
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=validate_size, shuffle=True)
# batch 函数
def get_batch(batchsize: int, X: np.ndarray, Y: np.ndarray):
assert 0 == X.shape[0]%batchsize, f'{X.shape[0]}%{batchsize} != 0'
batchnum = X.shape[0]//batchsize
X_new = X.reshape((batchnum, batchsize, X.shape[1]))
Y_new = Y.reshape((batchnum, batchsize, ))
for i in range(batchnum):
yield X_new[i, :, :], Y_new[i, :]
# 损失函数
def mse(X: np.ndarray, Y: np.ndarray, W: np.ndarray):
return 0.5 * np.mean(np.square(X@W-Y))
def diff_mse(X: np.ndarray, Y: np.ndarray, W: np.ndarray):
return X.T@(X@W-Y) / X.shape[0]
# 模型训练
lr = 0.001 # 学习率
num_epochs = 1000 # 训练周期
batch_size = 64 # |每个batch包含的样本数
validate_every = 4 # 多少个周期进行一次检验
def train(num_epochs: int, batch_size: int, validate_every: int, W0: np.ndarray, X_train: np.ndarray, Y_train: np.ndarray, X_test: np.ndarray, Y_test: np.ndarray):
loop = tqdm(range(num_epochs))
loss_train = []
loss_validate = []
W = W0
# 遍历epoch
for epoch in loop:
loss_train_epoch = 0
# 遍历batch
for x_batch, y_batch in get_batch(64, X_train, Y_train):
loss_batch = mse(X=x_batch, Y=y_batch, W=W)
loss_train_epoch += loss_batch*x_batch.shape[0]/X_train.shape[0]
grad = diff_mse(X=x_batch, Y=y_batch, W=W)
W = W - lr*grad
loss_train.append(loss_train_epoch)
loop.set_description(f'Epoch: {epoch}, loss: {loss_train_epoch}')
if 0 == epoch%validate_every:
loss_validate_epoch = mse(X=X_test, Y=Y_test, W=W)
loss_validate.append(loss_validate_epoch)
print('============Validate=============')
print(f'Epoch: {epoch}, train loss: {loss_train_epoch}, val loss: {loss_validate_epoch}')
print('================================')
plot_loss(np.array(loss_train), np.array(loss_validate), validate_every)
# 程序运行
W0 = np.random.random(size=(X.shape[1], )) # 初始权重
train(num_epochs=num_epochs, batch_size=batch_size, validate_every=validate_every, W0=W0, X_train=X_train, Y_train=Y_train, X_test=X_test, Y_test=Y_test)
BP算法就是反向传播,要输入的数据经过一个前向传播会得到一个输出,但是由于权重的原因,所以其输出会和你想要的输出有差距,这个时候就需要进行反向传播,利用梯度下降,对所有的权重进行更新,这样的话在进行前向传播就会发现其输出和你想要的输出越来越接近了。
近期在投一些实习岗位,越来越觉得很多HR猎头其实并不知道自己公司想要什么人,他们不会去看你复现过什么论文,项目代码结构,以及行业的匹配度,在找大模型算法岗位结果上来很多问你来不来开发运维岗的,5月份暑期hc没几个了甚至秋招提前批都开始了,但有些厂频频找上门总给人营造一种门庭若市的假象,这些事情总是让我很疲惫,我开始怀念大一单纯写数学题的日子。事实上,只要把CV包装下基本都解决了,感觉小廖帮我修改的简历。
监督学习
回归算法:从可能的数字中预测算法,学习算法提供例子,xy映射
分类算法:拟合边界线,分辨哪个type
无监督学习
聚类算法:获取没有标签的数据并尝试自己将他们分组到集群中,只是分类 ···
逻辑结构:线性结构,树形结构,图形结构
线性数据结构:线性数据结构是指数据元素之间存在一对一的线性关系的数据结构。常见的线性数据结构包括数组、广义表,链表、栈和队列
核心:计算
五大功能部件:输入设备,运算器,存储器,控制器,输出设备。运作方式?
容量大,断电后依然可以保存数据,无法直接从其中取数据用,必须把数据调入内存后才能使用,访问速度慢;
引导程序:当计算机开机运行时,需要运行一个初始程序,位于计算机的固件,如只读内存ROM,将操作系用内核加载到内存中,除了内核外,一些服务也会在启动时加到内存成为系统程序或后台,一旦完成,系统完全启动,等待事件发生(如触发一个软件)
外部是可见性关键词,内部是所有实例共享static的变量,静态类成员变量属于全体实例,所以任意实例不能给静态变量分配内存,要用类使用变量,static让被修饰的语句具有唯一性,确定性
栈
LIFO
用数组模拟栈
int st[N];//元素数量,栈顶下标
//压栈
st[++*st]=var1;
//取栈顶
int u =st[*st];
//弹栈,*st==0时不能继续弹出
if(*st) --*st;
//清空栈
*st =0 ;
STL中的栈
//引入stack头文件,container默认使用stf::deque
template<
class T,class Container = std:deque<T>
>class stack;
容器必须提供以下函数,如std::vector,std::deque和std::list
小红书爬虫
python main.py --paltform xhs --lt qrcode --type search
修改了config下的配置文件,最好不要开并发,会发现爬了一段时间爬不了,修改keywords为实体清单,db_config为nkuwiki数据库配置,使用GET_IMAGES和GET_COMMENT,分两次爬取,一次导入数据库,一次导入本地以json格式,改START_DAY和END_DAY
数组
二分法
class Solution {
public:
int search(vector<int>& nums, int target) {
int left = 0 ;
int right =nums.size()-1;
while (left <= right ){
int middle = left + ((right-left)/2);
if (target < nums[middle]){
right = middle-1;
} else if (target > nums[middle]){
left = middle+1;
}else{
return middle;
}
}
return -1;
}
};
翻转链表
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* temp;
ListNode* cur = head;
ListNode* pre = NULL;
while(cur){
temp=cur->next;//暂时保存cur的下一个节点
cur->next=pre;//反转
pre=cur;//更新pre和cur指针
cur=temp;
}
return pre;
}
};
环形链表
Unix is a user-friendly. It’s just selective about who its friends are.
Unix哲学
KISS:Keep it simple,stupid.
Everything is a file and pipeline programs to work together.
每个工具只做一件事情,但做到极致
小工具统一文本输入输出,易于使用
使用管道进行组合
由于引导区空间有限,只有512个字节,故打算把程序编译成com文件,然后让DOS执行
nasm pmtest1.asm -o pmtest1.com
一些挂载问题:
1、写入空白内容:
dd if=/dev/null of=pm.img bs=512 count=1 conv=notrunc
2、使用 losetup 命令,将 data.img 作为 loop device 使用:
sudo losetup /dev/loop0 pm.img
3、然后,格式化这个 loop device:
sudo mkfs.msdos /dev/loop0
4、检查文件系统:
sudo fsck.msdos /dev/loop0
5、删除 loop device:
sudo losetup -d /dev/loop0
这时候,pm.img 已经格式化完成,可以作为一个软盘镜像使用。用file查看,结果为:
pm.img: DOS floppy 1440k, x86 hard disk boot sector
再次输入
sudo mount -o loop pm.img /mnt/floppy
6、挂载成功!!!
之后正常挂在就行
gcc hello.c -save-temps –verbose
-save-temps保存中间生成文件
–verbose查看详细工具流
gcc -E hello.c -o hello.i
gcc -S hello.c -o hello.s
gcc -c hello.s -o hello.o
重定向文件
反汇编
一些常见的逆向函数
index() find()找索引值
.append(ord()) +=chr()字母数字转换
简简单单的逻辑题
ord 字符串转ascii码
chr ascii码转字符串
hex 十进制转十六进制
int(a,16) 十六进制转十进制
[起点,终点,步长] python切片
zfill(2) 为不满2个宽度的字符串前添加0直到宽度为2
easy C
直接逆完事
编辑:vim/edit
编译:masm
链接:link
将内存2000:0,2000:1,2000:2,2000:3单元中的数据送入al,bl,cl,dl中
好想成为和他一样优秀的人
# F系列【主要是调试状态的处理】
F2 添加/删除断点
F4 运行到光标所在位置
F5 反汇编
F7 单步步入
F8 单步跳过
F9 持续运行直到输入/断点/结束
shift系列【主要是调出对应的页面】
shift+F1 Local types
shift+F2 execute scripts【常用】
shift+F3 Functions
shift+F4 Names
shift+F5 Signatures
shift+F7 Segments
shift+F8 Segments registers
shift+F9 Structures
shift+F10 Enumerations
shift+F11 Type libraries
shift+F12 Strings【常用】
Shift+E 导出数据【常用】
# 单字符系列【基本是数据处理转换相关】【这些都比较常用】
G 按地址查找
D 将字符串等元素转为数据
N 重命名(函数名、变量名等)
Y 修改变量类型等(比如int改char等等)
H decimal 数据的进制快速转换
A 将数据转变为字符串类型
C code(将数据转变为汇编代码,分为自动和强制执行)
U undefined(将字符串转变为原始数据)
X 交叉引用(反汇编页面)
P 选中位置识别为函数
# Ctrl、Alt系列
Ctrl+F 搜索【常用】
Ctrl+X 交叉引用(汇编页面)【常用】
Alt+T 查找Text
Ctrl+T 查找下一个text
Alt+C Next Code
Ctrl+D Next Data
Ctrl+Z 撤销
Ctrl+Shift+Z 恢复
Alt+K 修改堆栈值
# else
/ 添加注释 or 右键选择edit comment【常用】
\ hide cast,隐藏/显示一些变量类型注解
Ins 添加区块注释
通用寄存器
- EAX:(针对操作数和结果数据的)累加器
- EBX:(DS段的数据指针)基址寄存器
- ECX:(字符串和循环操作的)计数器
- EDX:(I/O指针)数据寄存器
- ESI:(字符串操作源指针)源变址寄存器
- EDI:(字符串操作目标指针)目的变址寄存器
- EBP:(SS段中栈内数据指针)扩展基址指针寄存器[栈帧寄存器、栈底指针寄存器]
- ESP:(SS段中栈指针)栈指针寄存器[指向栈顶]
段寄存器
- CS:代码段寄存器
- SS:栈段寄存器
- DS:数据段寄存器
- FS:数据段寄存器
- ES:附加数据寄存器
- GS:数据段寄存器
程序状态与控制寄存器
- EFLAGS:标志寄存器,32个位元的01控制
- ZF(零标志器,运算结果为0时置1)
- CF(进位标志,运算结果向最高位以上进位时置1)
- OF(溢出标志)
- AF(辅助进位标志,运算结果在第3位的时候置1)
- SF(符号标志,有符号整型的符号位为1时置1)
指令指针寄存器
常用指令
操作码 目的操作数 源操作数
总体:X
个体:Xi
样本:(X1,X2,…….Xn)随机变量
样本值:n个独立样本的一次实现(x1,x2,…….xn)具体的数
web2:view-source是一种协议,早期基本上每个浏览器都支持这个协议。后来Microsoft考虑安全性,对于WindowsXP pack2以及更高版本以后IE就不再支持此协议。但是这个方法在FireFox和Chrome浏览器都还可以使用。 如果要在IE下查看源代码,只能使用查看中的"查看源代码"命令.以前的使用方法:在浏览器地址栏中输入 view-source: URL
HTTP请求:抓包,把GET换成CTFHUB
302跳转:网页临时移动到新的位置,而浏览器的缓存没有更新,flag在index.php下而跳转到index.html打开burp suite抓包,发送请求
UDP TCP 客户端 服务器
socket实例化
socket(family,type,[protocal])协议族(默认AF_INET),,SOCK_STREAM(TCP)/SOCK_DGRAM(UDP)
如果成为脚本小子,只是说明对底层原理不理解,说的是本人
Web应用程序
| 缺陷 |
真实场景 |
|
SQL 注入 |
获取 Active Directory 用户名并对 VPN 或电子邮件门户执行密码喷洒攻击。 |
|
文件包含 |
阅读源代码以查找隐藏的页面或目录,这些页面或目录公开了可用于获取远程代码执行的附加功能。 |
|
不受限制的文件上传 |
允许用户上传个人资料图片的 Web 应用程序,允许上传任何类型的文件(不仅仅是图片)。可以利用此功能通过上传恶意代码来完全控制 Web 应用程序服务器。 |
|
不安全的直接对象引用(IDOR) |
当与访问控制失效等缺陷相结合时,这通常可用于访问其他用户的文件或功能。例如,在浏览到 /user/701/edit-profile 等页面时编辑您的用户个人资料。如果我们可以将 更改701为702,我们就可以编辑其他用户的个人资料! |
|
访问控制失效 |
另一个示例是允许用户注册新帐户的应用程序。如果帐户注册功能设计不佳,用户可能会在注册时执行权限提升。考虑POST注册新用户时的请求,该请求提交数据username=bjones&password=Welcome1&email=bjones@inlanefreight.local&roleid=3。如果我们可以操纵roleid参数并将其更改为0或会怎样1?我们已经看到了这种情况的真实应用程序,并且可以快速注册管理员用户并访问 Web 应用程序的许多非预期功能。 |
Web程序布局
层:
发现主机
sudo nmap 10.129.2.0/24 -sn -oA tnet | grep for | cut -d" " -f5
| 扫描选项 |
描述 |
10.129.2.0/24 |
目标网络范围。 |
-sn |
禁用端口扫描。 |
-oA tnet |
以名称“tnet”开头的所有格式存储结果。 |
Firewall and IDS Evasion此扫描方法仅在主机的防火墙允许的情况下才有效
因为不想复习数据库所以在玩sqli
记号
如果$n_1+n_2+\cdots+n_r=n$, 则定义$\binom n{n_1,n_2,\ldots,n_r}$为
$$\binom n{n_1,n_2,\cdots,n_r}=\frac{n!}{n_1!n_2!\cdots n_r!}$$因此,$\binom n{n_1,n_2,\ldots,n_r}$表示把 $n$ 个 不 同 的 元 素 分 成 大 小 分 别 为 $n_1, n_2, \ldots , n_r$的$r$个
第二章 关系数据库
1.试述关系模型的三个组成部分
关系数据结构:只包含单一的数据结构——关系,由三种类型:基本关系(基本表),查询表和视图表
关系操作集合:查询(选择,投影,并,差,笛卡尔积),插入,删除,修改
第一章 绪论
1.试述数据,数据库,数据库管理系统,数据库系统的概念
- 数据:描述事物的符号
- 数据库DB:长期储存在计算机内,有组织的,可共享的大量数据的集合。数据库中的数据按一定的数据模型组织,描述和储存,具有较小的冗余度,较高的数据独立性和易扩展性,并可为各种用户共享
- 数据库管理系统DBMS:系统软件,有以下功能:
- 数据定义
- 数据组织,存储和管理
- 数据操纵功能
- 数据库的事务管理和运行管理
- 数据库建立和维护
- 数据库系统DBS:由DB,DBMS,DA组成的存储,管理,处理和维护数据的系统
2.使用数据库有什么好处?
SELECT RTRIM(vend_name) + '('+ --右边取消空格
RTRIM(vend_country) + ')'
AS vend_title
From Vendors
ORDER BY vend_name;
SELECT prod_id,quantity,item_price,quantity*item_price
AS expanded_price
FROM OrderItems;
SELECT vend_name,UPPER(vend_name) --大写
AS vend_name_upcase
FROM Vendors
ORDER BY vend_name;
SELECT cust_name,cust_contact
FROM Customers
WHERE SOUNDEX(cust_contact) = SOUNDEX('Michael Green'); --近似发音
SELECT order_num
FROM Orders
WHERE DATEPART(yy,order_date) = 2020;
SELECT AVG(prod_price) AS avg_price --取平均值
FROM Products
WHERE vend_id = 'DLL01';
SELECT COUNT(*)AS num_cust --对所有行计数
FROM Customers;
SELECT MAX(prod_price) AS max_price
FROM Products;
SELECT SUM(quantity*item_price) AS
items_ordered
FROM OrderItems
WHERE order_num = 20005;
SELECT AVG(DISTINCT prod_price) AS avg_price
FROM Products
Where vend_id ='DLL01';
SELECT COUNT(*) AS num_items,MIN(prod_price) AS price_min,MAX(prod_price) AS proce_max,AVG(prod_price) AS price_avg --组合聚集函数
FROM products;
SELECT vend_id,COUNT(*) AS num_prods
FROM Products
Group BY vend_id
HAVING COUNT(*) >= 2;--过滤分组,group by 和 having结合
SELECT order_num,COUNT(*)AS items
FROM OrderItems
Group BY order_num
HAVING COUNT(*) >= 3--检索包含三个或更多物品的订单号和订购物品的数目
ORDER BY items,order_num;--按订购物品的数目排序输出,having在group by前,order by后
SELECT cust_id
FROM OrderItems
WHERE prod_id = 'RGAN01';
SELECT cust_id
FROM Orders
WHERE order_num IN (20007,20008);
SELECT cust_id
FROM Orders
WHERE order_num IN (SELECT cust_id
FROM Orders
WHERE order_num IN (20007,20008));--建立以上的子查询,由内向外
SELECT cust_name,cust_state,(SELECT COUNT(*)FROM Orders WHERE Orders.cust_id=Customers.cust_id) AS orders --子查询对检索出的每个顾客执行一次,用句点避免混淆列名
FROM Customers
ORDER BY cust_name;--对于检索出的每个顾客,统计其在Orders表中的订单数目
SELECT vend_name,prod_name,prod_price
FROM Vendors,Products
WHERE Vendors.vend_id = Products.vend_id;
BEGIN TRANSACTION
DELETE OrderItems WHERE order_num =12345
SAVE TRANSACTION delete1;--使用保留点delete1,保留点越多越好,额能进行灵活的回退
DELETE Orders
WHERE order_num =12345
ROLLBACK TRANSACTION delete1;--回退到保留点delete1
COMMIT TRANSACTION--控制事物处理,最后的commit仅在中间过程不出错的情况下写出更改
BEGIN TRANSACTION
DELETE OrderItems WHERE order_num =12345
SAVE TRANSACTION delete1;--使用保留点delete1,保留点越多越好,额能进行灵活的回退
DELETE Orders
WHERE order_num =12345
ROLLBACK TRANSACTION delete1;--回退到保留点delete1
COMMIT TRANSACTION--控制事物处理,最后的commit仅在中间过程不出错的情况下写出更改
DECLARE CURSOR CustCursor
IS
SELECT * FROM Customers
WHERE cust_email IS NULL;
ALTER TABLE Vendors
ADD CONSTRAINT
PRIMARY KEY(vend_id)--设置主键,DBMS默认主键基本不修改或更新,不能重用
ALTER TABLE Orders
ADD CONSTRAINT
FOREIGN KEY (cust_id) REFERENCES Customers(cust_id);--将此表中的cust_id设置为Customers的主键,即外键。外键有助防止意外删除,若删除,级联删除
CREATE INDEX prod_name_ind--索引名
ON Products(prod_name)--被索引的表,列
CREATE TRIGGER customer_state
ON Customers
FOR INSERT,UPDATE
AS
UPDATE Customers
SET cust_state=Upper(cust_state)
WHERE Customers.cust_id = inserted.cust_id;--创建一个触发器,对所有INSERT和UPDATE操作,将cust_state转为大写
Python
JS
做个代办事项列表(我所能想到JS对我的唯一用处就是网页加个响应什么的)
重新巩固C语言
Unity
学习C#语言,可能大创写个游戏,或者跟之前联系好的设计系朋友写着玩玩
Python
基础语法到面向对象编程,小项目只用过pygame写了一个窗口射击游戏,图灵系列那本python编程学的很流畅,很快能上手项目
Javascript
到现在只学了点皮毛,只会做动态内容更新,也只是自己做html网页时乱加上去的
import java.util.Scanner;
public class Main{
public static void main(String[] args){
Scanner scanner = new Scanner(System.in);
System.out.print("Enter your name:");
String name=scanner.nextLine();
scanner.close();
}
}
println最后会自动生成一个换行符
继承
需要注意的是 Java 不支持多继承,但支持多重继承。
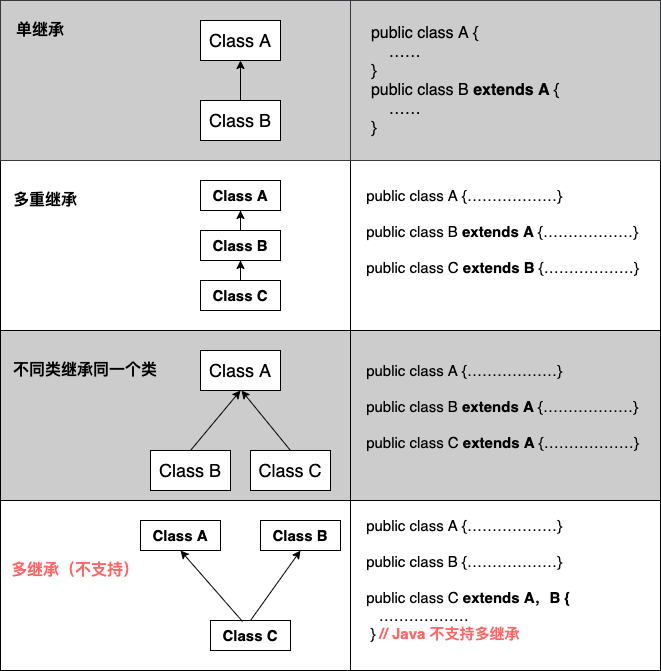
extends
extend只能继承一个父类
Openai盲区
默认情况下,当你向 OpenAI API 发起请求时,我们会先生成模型的全部输出,然后再通过一个 HTTP 响应发送回来。在生成长输出时,等待响应可能需要较长时间。流式传输响应允许你在模型继续生成完整响应的同时,开始打印或处理输出的开头部分。
agent
Agent是一个能感知并自主地采取行动的实体,这里的自主性极其关键,Agent要能够实现设定的目标,其中包括具备学习和获取知识的能力以提高自身性能。
构建Chatbot的本质
不断切换角色获取上下文,例如
def collect_messages(_):
prompt = inp.value_input
inp.value = ''
context.append({'role':'user', 'content':f"{prompt}"})
response = get_completion_from_messages(context)
context.append({'role':'assistant', 'content':f"{response}"})
panels.append(
pn.Row('User:', pn.pane.Markdown(prompt, width=600)))
panels.append(
pn.Row('Assistant:', pn.pane.Markdown(response, width=600, style={'background-color': '#F6F6F6'})))
return pn.Column(*panels)
给定身份
system message:提供了一个总体的指示。系统消息则有助于设置助手的行为和角色,并作为对话的高级指示。你可以想象它在助手的耳边低语,引导它的回应,而用户不会注意到系统消息
第三章 SQL
1.试述SQL的特点
综合统一,高度非过程化,面向集合的操作方式,以同一种语法结构提供多种使用方式
2.说明在DROP TABLE时,RESTRICT和CASCADE的区别